
AI Text Datasets
An AI text dataset refers to a structured collection of textual data that is used for training, evaluating, and validating machine learning models, particularly in the field of natural language processing (NLP). These datasets are essential for teaching AI systems to understand, generate, and manipulate human language. They can vary in size, format, and content, depending on the specific application or research focus.
Where can you download AI text dataset from
Hugging face maintains links to popular datasets. You can find these AI text datasets by clicking on the following link:
AI text datasets at Huggingface
Most popular AI text dataset authors
Our favourite AI text dataset
Our favourite dataset is OpenMathInstruct-2 because it is an excellent demonstration of how a dataset can be generated and used to train and evaluate AI models.
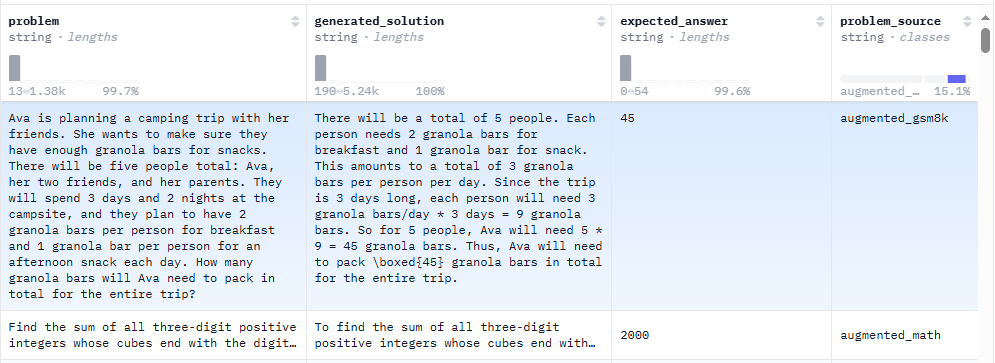
OpenMathInstruct-2 is a math instruction tuning dataset with 14M problem-solution pairs generated using the Llama3.1-405B-Instruct model.
The training set problems of GSM8K and MATH are used for constructing the dataset in the following ways:
Solution augmentation: Generating chain-of-thought solutions for training set problems in GSM8K and MATH. Problem-Solution augmentation: Generating new problems, followed by solutions for these new problems.
This dataset can be downloaded from:
https://huggingface.co/datasets/nvidia/OpenMathInstruct-2
Key Characteristics of AI Text Datasets
- Content Type: The datasets can contain different types of text, such as:
- Articles
- Books
- Reviews
- Social media posts
- Emails
- Transcripts of spoken language
- Labeling: Many text datasets are labeled for supervised learning tasks. For example, a sentiment analysis dataset might label texts as "positive," "negative," or "neutral." Labeling helps the model learn the relationship between the input data (text) and the desired output (label).
- Size and Diversity: AI text datasets can range from small collections of a few hundred samples to massive corpora with billions of words. Diverse datasets help models generalize better across different contexts, languages, and styles.
- Structure: Datasets can be structured or unstructured:
- Structured: Organized in a specific format, like CSV or JSON, where each row represents a sample, and columns represent features (e.g., text, label, metadata).
- Unstructured: Raw text data without a predefined structure, often requiring preprocessing to make it usable for machine learning tasks.
- Domain-Specific vs. General Purpose: Some datasets are tailored for specific applications (e.g., medical texts, legal documents), while others are more general (e.g., Wikipedia articles, news articles).
Examples of Common AI Text Datasets
- IMDB Reviews: A dataset of movie reviews labeled as positive or negative, commonly used for sentiment analysis tasks.
- 20 Newsgroups: A collection of approximately 20,000 newsgroup documents, partitioned across 20 different newsgroups, useful for topic classification tasks.
- Common Crawl: A massive dataset containing web pages collected from the internet, providing diverse text for various NLP tasks.
- SQuAD (Stanford Question Answering Dataset): A reading comprehension dataset containing questions based on Wikipedia articles, where the model must extract answers from the text.
- CoNLL 2003: A dataset for named entity recognition (NER) tasks, consisting of annotated text with entities like persons, organizations, and locations.
Applications of AI Text Datasets
- Training Machine Learning Models: Used to train models for tasks like text classification, sentiment analysis, language translation, and summarization.
- Benchmarking and Evaluation: Provides a standard way to evaluate the performance of different NLP models.
- Research: Facilitates research in linguistic phenomena, model architectures, and new learning algorithms.
- Fine-Tuning Pre-trained Models: Used for fine-tuning models like BERT or GPT on specific tasks or domains.
Conclusion
AI text datasets are foundational to developing and training natural language processing systems. They provide the necessary data for models to learn language patterns, enabling a wide range of applications, from chatbots to sentiment analysis tools. The quality, diversity, and relevance of the dataset are crucial factors that significantly impact the performance and effectiveness of AI models in understanding and generating human language.